JPA를 사용하다 보면 가장 자주 마주하게 되는 이슈가 N+1이다. N+1이 발생할 때 데이터의 양이 아주 적으면 그냥 무심코 넘길 수 있지만 데이터가 많아질수록 성능에서 엄청난 차이를 가져온다.
이번 포스팅에서는 문제가 발생하는 예시와 해결 방안에 대해서 정리하려 한다.

Post를 호출하여 Comment를 사용할 것이다라고 가정하자.
➡️엔티티 클래스
post
@Entity
@Getter
@NoArgsConstructor
public class Post {
@Id@GeneratedValue
@Column(name = "post_id")
private Long id;
private String name;
@OneToMany(mappedBy = "post",cascade = CascadeType.ALL,fetch = FetchType.LAZY)
private List<Comment> comments = new ArrayList<>();
@Builder
public Post(String name, List<Comment> comments) {
this.name = name;
if(comments != null){
this.comments = comments;
}
}
public void addComment(Comment comment){
this.comments.add(comment);
comment.updatePost(this);
}
}comment
@Entity
@Getter
@NoArgsConstructor
public class Comment {
@Id@GeneratedValue
private Long id;
private String content;
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "post_id")
private Post post;
@Builder
public Comment(String content, Post post) {
this.content = content;
this.post = post;
}
public void updatePost(Post post){
this.post = post;
}
}Repository
@Repository
public interface PostRepository extends JpaRepository<Post,Long> {
}Service
@RequiredArgsConstructor
@Slf4j
@Service
public class PostService {
private final PostRepository postRepository;
@Transactional(readOnly = true)
public List<String> findAllComments() {
return extractSubjectNames(postRepository.findAll());
}
private List<String> extractSubjectNames(List<Post> posts) {
log.info("Comments Size : {}", posts.size());
return posts.stream()
.map(a -> a.getComments().get(0).getContent())
.collect(Collectors.toList());
}
}ServiceTest
@SpringBootTest
class PostServiceTest {
@Autowired
private PostRepository postRepository;
@Autowired
private PostService postService;
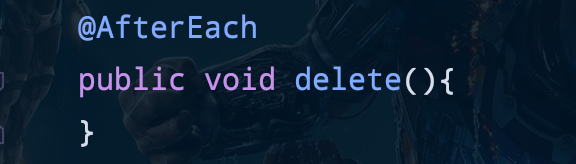
@BeforeEach
public void setUp(){
List<Post>posts = new ArrayList<>();
for(int i = 0; i< 10; i++){
Post post = Post.builder()
.name("게시글"+i)
.build();
post.addComment(Comment.builder()
.content("댓글"+i)
.build());
posts.add(post);
}
postRepository.saveAll(posts);
}
@Test
@DisplayName("게시글 조회시 댓글 조회 N+1 발생")
void N_plus_1_O()throws Exception{
List<String> comments = postService.findAllComments();
assertThat(comments.size()).isEqualTo(10);
}
}
위 테스트 코드를 실행하면 아래처럼 Post를 조회하는 쿼리와 Post의 자신의 Comment를 조회하는 쿼리가 10번이 나간다.

이게 오늘 정리하는 N+1 쿼리이다.
위처럼 하위 엔티티를 한 번에 가져오지 않고 지연 로딩으로 필요한 곳에서 사용되어 쿼리가 실행될 때 발생하는 문제이다.
지금은 Post가 10개이니 처음 조회되는 쿼리 한 번과 10번의 Comment조회가 발생하여 총 11번의 쿼리가 발생한다.
지금은 11번만 나가지만 조회 결과가 1만 개면 DB 조회가 최소 1만 번은 일어나서 성능이 급격하게 저하된다.
이제 이러한 문제에 대한 해결책을 보자.
1.fetch join
@Query("select a from Post a join fetch a.comments")
List<Post>findAllFetchJoin();fetch join은 바로 가져오고 싶은 Entity 필드를 지정하는 것이다.
@Test
@DisplayName("fetchjoin으로 게시글 가져옴")
void fetchJoin_getPost()throws Exception{
List<Post> post = postRepository.findAllFetchJoin();
assertThat(post.size()).isEqualTo(10);
}
테스트 코드를 실행하면 쿼리가 한 줄만 실행된다.
이로써 문제는 해결되지만 불필요한 쿼리문이 추가된다는 단점이 존재한다.
필드마다 Eager.Lazy 방식을 다르게 해서 쿼리가 불필요하면 @EntityGraph를 사용하면 된다.
2.EntityGraph
@EntityGraph의 attributePaths에 쿼리 수행 시 바로 가져올 필드명을 지정하면 Lazy가 아닌 Eager로 조회가 된다.
@EntityGraph(attributePaths = "comments")
@Query("select a from Post a")
List<Post> findAllEntityGraph();위처럼 원본 쿼리의 손상 없이 (Eager/Lazy) 필드를 정의하고 사용할 수 있게 된다.
테스트 코드를 작성해보자
@Test
@DisplayName("게시글 여러개를 EntityGraph 로 가져온다.")
void entityGraph()throws Exception{
List<Post> post = postRepository.findAllEntityGraph();
assertThat(post.size()).isEqualTo(10);
}

테스트 코드 결과를 보면 정상적으로 조회 쿼리가 작동한다.
두 방식 모두 카테시안 곱이 발생하여 comment의 수만큼 Post가 중복 발생하게 된다.
FetchJoin은 InnerJoin이고, @EntityGraph는 OuterJoin이다.
➡️fetchJoin
select
post0_.post_id as post_id1_3_0_,
comments1_.id as id1_1_1_,
post0_.name as name2_3_0_,
comments1_.content as content2_1_1_,
comments1_.post_id as post_id3_1_1_,
comments1_.post_id as post_id3_1_0__,
comments1_.id as id1_1_0__
from post post0_
inner join comment comments1_
on post0_.post_id=comments1_.post_id➡️@EntityGraph
select post0_.post_id as post_id1_3_0_,
comments1_.id as id1_1_1_,
post0_.name as name2_3_0_,
comments1_.content as content2_1_1_,
comments1_.post_id as post_id3_1_1_,
comments1_.post_id as post_id3_1_0__,
comments1_.id as id1_1_0__
from post post0_ left
outer join comment comments1_
on post0_.post_id=comments1_.post_id위 쿼리문은 위 두 방식의 조회 쿼리이다. 이제 중복을 확인해보자
@BeforeEach
public void setUp(){
List<Post>posts = new ArrayList<>();
for(int i = 0; i< 10; i++){
Post post = Post.builder()
.name("게시글"+i)
.build();
post.addComment(Comment.builder(
.content("댓글"+i)
.build());
post.addComment(Comment.builder()
.content("댓글1"+i)
.build());
posts.add(post);
}
postRepository.saveAll(posts);
}
@Test
@DisplayName("Posts여러개를_joinFetch로_가져온다")
void postFetchJoin() throws Exception {
//given
List<Post> posts = postRepository.findAllFetchJoin();
List<String> comments = postService.findAllSubjectNamesByJoinFetch();
//then
assertThat(posts.size()).isEqualTo(20);
assertThat(comments.size()).isEqualTo(20);
System.out.println("post size : " + posts.size());
System.out.println("comments size : " + comments.size());
}
테스트 코드를 실행해보면 Post의 개수가 10개가 아닌 20개로 생성된다.
이 문제의 해결법을 해결하는 데는 2가지의 방법이 있다.
첫 번째는 @OneToMany 필드를 Set 선언해주면 된다. Set은 중복을 허용하지 않아서 하나의 해결 방법이 된다.
@OneToMany(mappedBy = "post",cascade = CascadeType.ALL,fetch = FetchType.LAZY)
private Set<Comment> comments = new LinkedHashSet<>();Set은 순서도 보장하지 않기 때문에 LinkedHashSet을 사용하면 순서도 보장이 된다.
그러나 List를 써야 하는 상황이라면 distinct을 사용하여 중복을 제거해주는 방식이다.
@Query("select DISTINCT a from Post a join fetch a.comments")
List<Post> findAllJoinFetchDistinct();@Test
@DisplayName("distinct_FetchJoin")
void distinct()throws Exception{
//given
List<Post> posts = postRepository.findAllJoinFetchDistinct();
//then
assertThat(posts.size()).isEqualTo(10);
System.out.println("post size : " + posts.size());
}
중복되지 않고 정상적으로 조회가 된다.
@EntityGraph(attributePaths = "comments")
@Query("select DISTINCT a from Post a")
List<Post> findAllEntityGraphDistinct();@Test
@DisplayName("distinct_EntityGraph")
void distinct_EntityGraph()throws Exception{
//given
List<Post> posts = postRepository.findAllEntityGraphDistinct();
//then
assertThat(posts.size()).isEqualTo(10);
System.out.println("post size : " + posts.size());
}
또한 정상적으로 작동한다.
두 방식 중 자신의 프로젝트 상황에 맞게 사용하면 된다.
🧑🏻💻예제 코드
https://github.com/ryudongjae/blog-ex
GitHub - ryudongjae/blog-ex: 📁블로그 예제 코드
📁블로그 예제 코드 . Contribute to ryudongjae/blog-ex development by creating an account on GitHub.
github.com
Reference
'Dev > SpringData' 카테고리의 다른 글
| JPA - Enum 타입 엔티티에서 커스텀 코드 DB에 넣기 (0) | 2024.10.27 |
|---|---|
| [JPA] 더티 체킹(Dirty Checking) (0) | 2021.12.22 |
| [JPA] 양방향 연관관계(무한 루프) (0) | 2021.12.14 |
| [Querydsl] Projection 정리 (0) | 2021.12.12 |
| [Querydsl] QueryDSL 사용법 정리 (0) | 2021.12.03 |